
DotnetSpider
DotnetSpider, a .NET standard web crawling library. It is lightweight, efficient
C#3941mit
4 months ago
crawlercross-platformcsharp
spider_man
SpiderMan,a base-on Broadway fast high-level web crawling & scraping framework f
Elixir23apache-2.0
9 months ago
crawlerdata-miningelixir
panther
A browser testing and web crawling library for PHP and Symfony
PHP2939mit
last month
chromedrivere2e-testinghacktoberfest
tushare
TuShare is a utility for crawling historical data of China stocks
Python12890bsd-3-clause
8 months ago
financefintechpandas
aws-pdf-textract-pipeline
:mag: Data pipeline for crawling PDFs from the Web and transforming their conten
TypeScript164mit
6 months ago
awsaws-cdkaws-textract

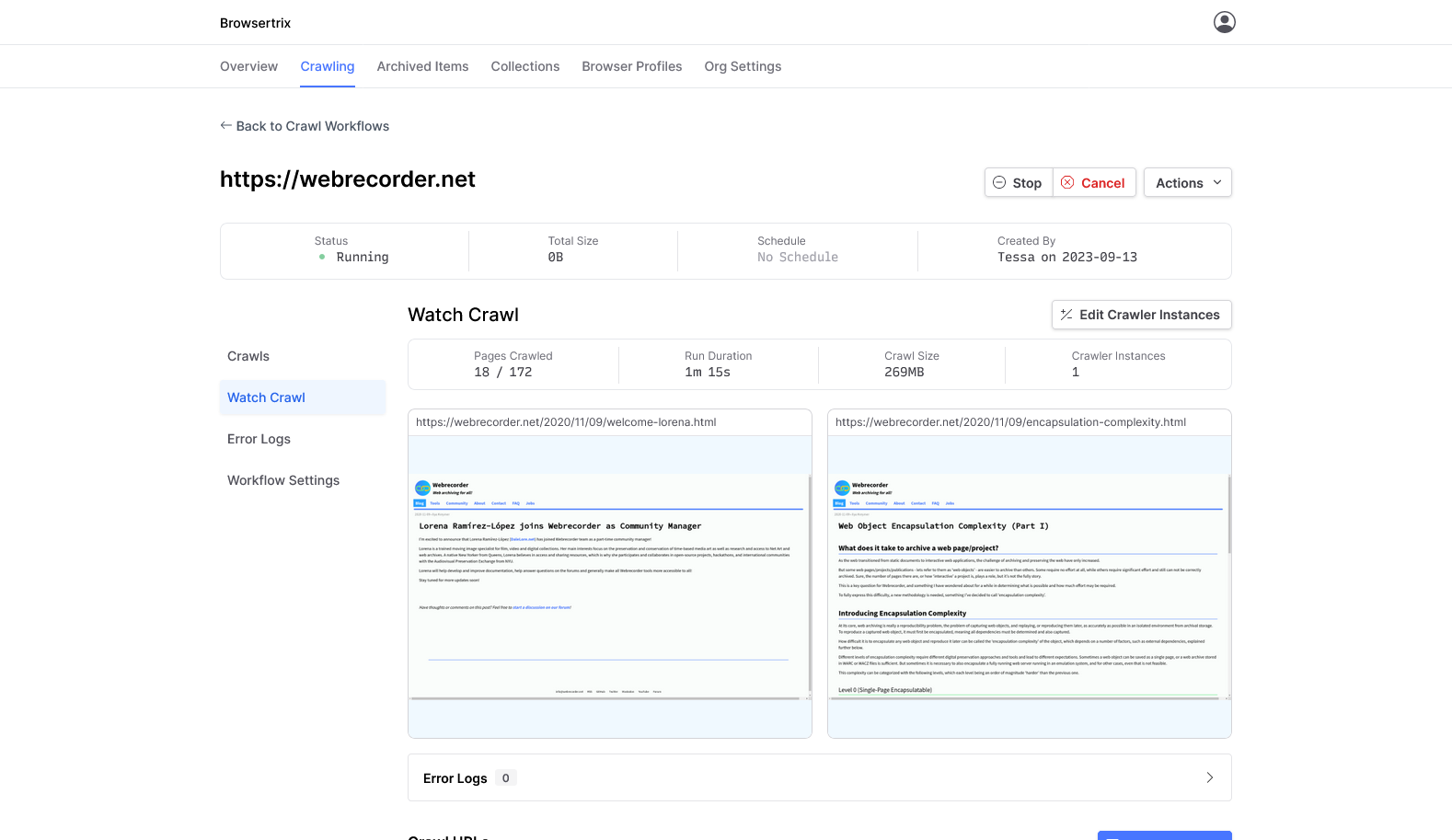
browsertrix
Browsertrix is the hosted, high-fidelity, browser-based crawling service from We
TypeScript149agpl-3.0
4 months ago
archivingcloudkubernetes

crawly
Crawly, a high-level web crawling & scraping framework for Elixir.
Elixir980apache-2.0
2 months ago
crawlercrawlingelixir
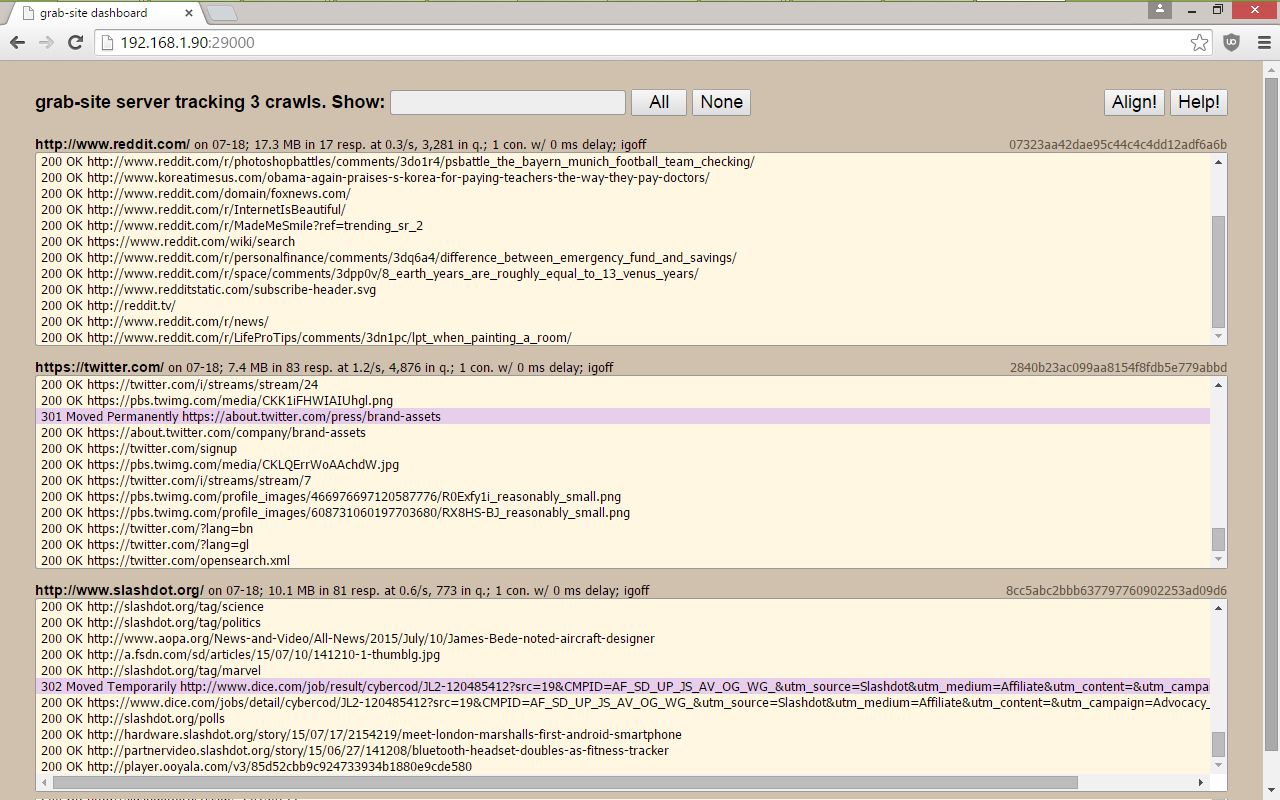
grab-site
The archivist's web crawler: WARC output, dashboard for all crawls, dynamic igno
Python1322other
5 months ago
archivingcrawlcrawler
node-readability
Scrape/Crawl article from any site automatically. Make any web page readable, no
JavaScript343
6 years ago
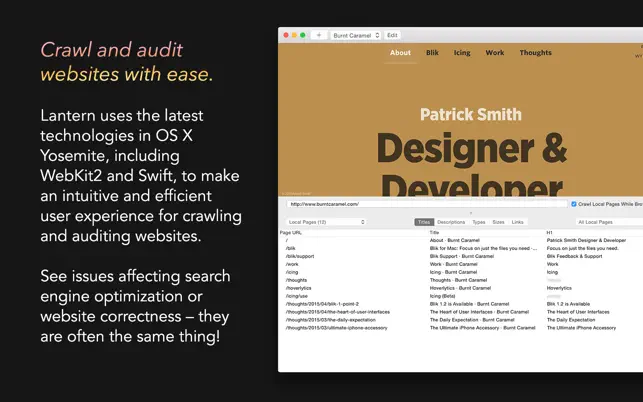
Lantern
Description Crawl and audit websites with ease.Build using the latest technol
Swift236apache-2.0
2 years ago
appmacmacos
antch
Antch, a fast, powerful and extensible web crawling & scraping framework for Go
Go258mit
4 years ago
crawlercrawlingframework
cc-notebooks
Various Jupyter notebooks about Common Crawl data
Jupyter Notebook47apache-2.0
2 years ago
aws-athenacommon-crawlcommoncrawl
egoboo
Egoboo is a working cool 3D dungeon crawling game in the spirit of NetHack for W
C++112gpl-3.0
2 years ago

aws-cdk-changelogs-demo
This is a demo application that uses modern serverless architecture to crawl cha
JavaScript277mit-0
last year
awsaws-fargateaws-lambda
streettraffic
StreetTraffic is a Python package that crawls the traffic flow data of your favo
Python28mit
7 years ago